
Systemy komunikacji zdarzeniowej (Message Brokers) umożliwiają luźne powiązanie między usługami i komponentami w organizacji lub projekcie, zapewniając jednocześnie asynchroniczną komunikację, skalowalność, wysoką przepustowość, niezawodność oraz bezpieczeństwo przesyłanych danych.
Apache Kafka to jeden z najpopularniejszych brokerów wiadomości, znany ze swojej wydajności i szeroko stosowany przez firmy takie jak Netflix, Uber czy LinkedIn. Ale czy rzeczywiście spełnia te oczekiwania? Czy zapewnia bezpieczeństwo danych, skalowalność i niezawodność? Czy działa optymalnie od razu po instalacji, czy wymaga dodatkowej konfiguracji?
Architektura Apache Kafka
W tej sekcji przedstawię i krótko omówię komponenty składające się na typową instalację Apache Kafka. Zrozumienie ich działania ułatwi nam dalszą analizę funkcjonalności i możliwości konfiguracji Kafki.
Jakie są podstawowe komponenty Apache Kafka?
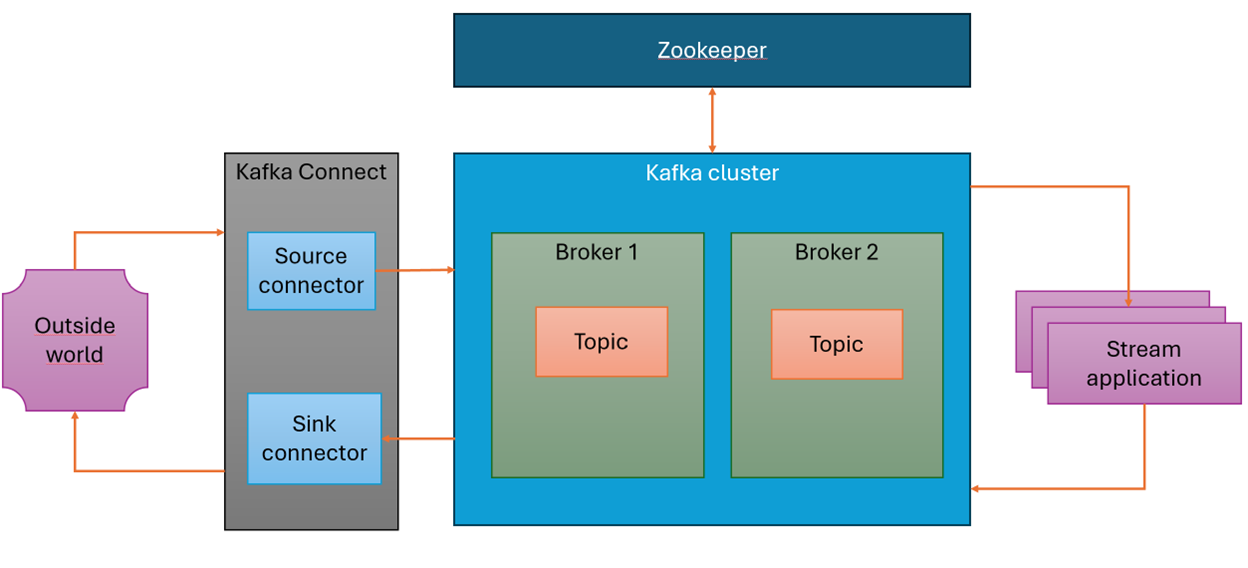
Powyższy diagram przedstawia typowe elementy składowe instalacji Apache Kafka. Kluczowym składnikiem jest klaster Kafka, który składa się z brokerów – serwerów odpowiedzialnych za przechowywanie i przetwarzanie danych.
Klaster zarządzany jest przez Apache Zookeeper (od wersji 2.8.0 wprowadzono alternatywne rozwiązanie – Kafka Kraft, które eliminuje konieczność korzystania z Zookeepera; od wersji 3.5.0 Zookeeper został oznaczony jako deprecated).
Każdy broker przechowuje dane w topicach, które są podzielone na partycje. Podział topicu na partycje odgrywa kluczową rolę w skalowalności i wydajności Kafki, ponieważ umożliwia równoległe przetwarzanie danych przez wielu konsumentów.
Czym jest partycjonowanie i kolejność wiadomości?
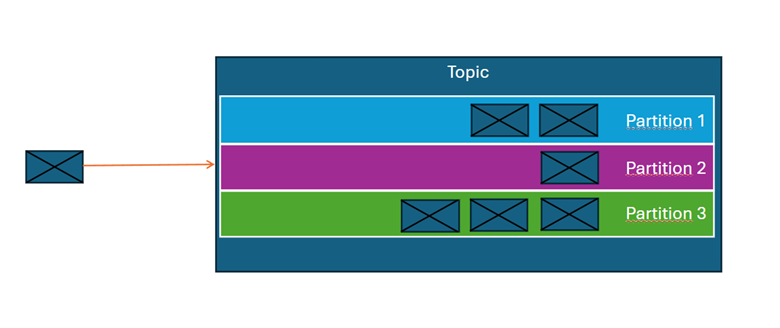
Podczas zapisywania wiadomości do topicu Kafka przypisuje je do konkretnej partycji na podstawie jednej z dwóch możliwości:
- Klucza partycjonowania – jeśli jest określony, wszystkie wiadomości z tym samym kluczem trafiają do tej samej partycji.
- Algorytmu round-robin – jeśli klucz nie jest określony, Kafka rozdziela wiadomości równomiernie pomiędzy dostępne partycje.
W obrębie pojedynczej partycji Kafka gwarantuje zachowanie kolejności wiadomości (według momentu zapisu), natomiast nie zapewnia globalnej kolejności między różnymi partycjami tego samego topicu. Każda wiadomość w partycji posiada unikalny identyfikator zwany offsetem, który pozwala na śledzenie przetwarzania danych przez konsumentów.
Czym jest grupa konsumentów i równoległe przetwarzanie?
Konsumenci Kafka są przypisani do grup konsumentów. Każdy konsument w grupie odczytuje wiadomości z jednej lub wielu partycji, jednak żadna partycja nie może być obsługiwana przez więcej niż jednego konsumenta w danej grupie.
Przykłady:
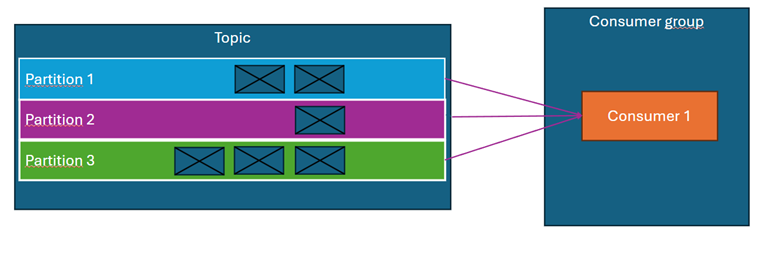
- Topic ma 3 partycje, a grupa konsumentów składa się z jednego konsumenta → konsument odbiera wiadomości ze wszystkich partycji. (diagram powyżej)
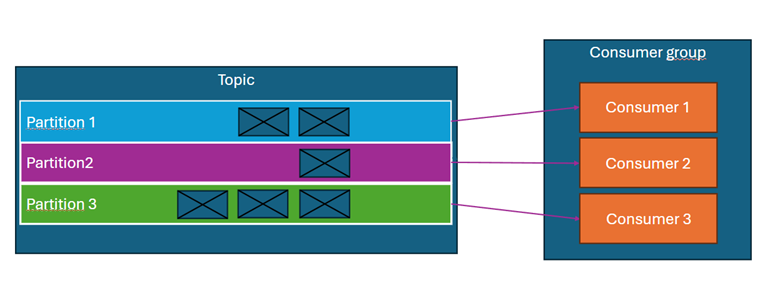
- Topic ma 3 partycje, a grupa składa się z 3 konsumentów → każdy konsument odbiera wiadomości z jednej partycji (diagram powyżej).
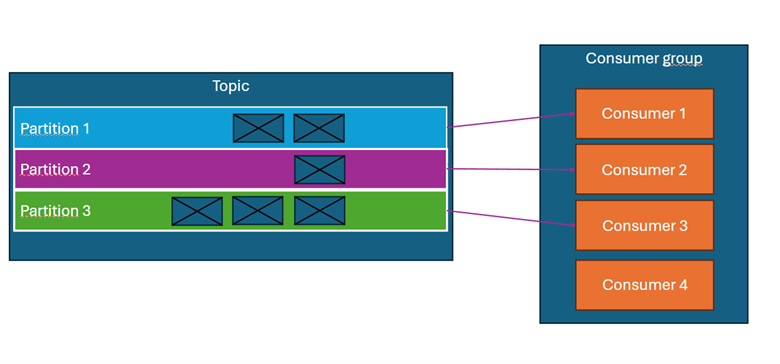
- Topic ma 3 partycje, a grupa składa się z 4 konsumentów → jeden z konsumentów pozostaje nieaktywny (diagram powyżej).
Grupę konsumentów można traktować jako aplikację Spring Boot lub Quarkus, a pojedynczego konsumenta jako wątek tej aplikacji. Dlatego podczas planowania przepustowości wdrażanego systemu należy odpowiednio dobrać liczbę partycji w topicach – to właśnie liczba partycji określa maksymalną liczbę wątków, które mogą równolegle przetwarzać wiadomości.
Rola brokera w klastrze Kafka
Każdy broker pełni kilka istotnych funkcji:
- Liderowanie partycjom – broker może być liderem dla wybranych partycji i obsługiwać ich operacje zapisu/odczytu.
- Replikacja danych – broker przesyła dane z partycji do innych serwerów klastra, zapewniając redundancję.
- Zarządzanie offsetami konsumentów (offset konsumenta = miejsce, gdzie dany konsument skończył czytać wiadomość)– broker przechowuje informację o tym, które wiadomości zostały już odczytane.
- Obsługa retencji danych z topicu– broker kontroluje usuwanie starszych danych zgodnie z polityką retencji ustawioną dla danego topicu w partycji.
Czym jest Kafka Connect? Jak kafka integruje się z innymi systemami?
Kolejnym elementem architektury jest Kafka Connect. To mechanizm umożliwiający integrację Kafki z innymi systemami, a tym samym komunikacje ze światem zewnętrznym. Składa się z dwóch typów konektorów:
- Source – konektory pozwalające na odczyt danych z systemów źródłowych (np. baz danych, systemów plików, S3) i przesyłanie ich do Kafki.
- Sink – konektory, które pobieraja/odczytują dane z wskazanych topiców Kafki i zapisują je w systemach docelowych (np. bazach danych, systemach plików, S3).
Na rynku dostępnych jest wiele gotowych konektorów. Do najpopularniejszych dostawców należą:
- Confluent → konektory Confluent (niektóre wymagają licencji).
- Camel → konektory Apache Camel (licencja Apache 2.0).
- io → konektory Lenses.io (licencja Open Source).
Warto zwrócić uwagę, że w przypadku Confluent licencja może się różnić w zależności od konektora – niektóre wymagają opłat, inne są open source. Czasami również konektor source i sink dla tego samego systemu mogą mieć różne licencje.
Ciekawą opcją są konektory Lenses.io, które oferują m.in. konektor JMS – wykorzystywaliśmy go w jednym z naszych projektów.
Znaczenie Stream Application – przetwarzanie danych w Kafce
Ostatnim elementem, przedstawionym na diagramie architektury jest Stream Application. To komponent, który pobiera dane z topicu, przetwarza je i zapisuje w topicu docelowym. Pełni jednocześnie rolę producenta i konsumenta wiadomości.
Aplikacje typu Stream Application mogą być tworzone w różnych frameworkach, takich jak:
- Spring Boot
- Quarkus
Typowe operacje realizowane przez Stream Applications obejmują:
- Transformaty wiadomości
- Przeliczanie
- Agregację, łączenie komunikatów z wielu topiców
Ostatnim elementem, przedstawionym na diagramie architektury, jest Stream Application. Jest to komponent, który pobiera dane z topicu, przetwarza i wysyła na topic docelowy. Innymi słowy grupuje w sobie funkcjonalność konsumenta i producenta Kafka. Aplikacje takie można wytwarzać w różnych frameworkach np. Spring Boot, Quarkus i mogą one realizować transformaty wiadomości, przeliczenia, agregaty, mogą łączyć komunikaty z kilku topiców.
Omówione powyżej komponenty stanowią podstawę architektury Apache Kafka. W kolejnych sekcjach przyjrzymy się ich konfiguracji i optymalizacji.
Kafka posiada bogatą dokumentację, a w Internecie można znaleźć wiele dodatkowych materiałów na jej temat. Warto na przykład zapoznać się z takimi elementami jak Schema Registry, które umożliwia zarządzanie schematami wiadomości przesyłanych w Kafce, a nie został omówiony powyżej.
Obszary funkcjonalne Apache Kafka
Zanim przejdziemy do szczegółowej analizy, warto omówić kluczowe obszary funkcjonalne, które powinien zapewniać broker wiadomości:
- Wdrażanie i konfiguracja – Broker (lub ekosystem narzędzi wokół niego) powinien umożliwiać łatwe wdrażanie komponentów, zarządzanie kolejkami i kontrolę dostępu do nich, a także elastyczne konfigurowanie systemu.
- Monitoring – Istotnym elementem działania brokera (lub ekosystemu narzedzi wokół brokera) jest możliwość monitorowania działania kompoenentów oraz zbierania kluczowych metryk, takich jak przepustowość, wykorzystanie zasobów (CPU/RAM), rozmiar kolejek i inne parametry operacyjne.
- Bezpieczeństwo – w tym zakresie broker powinien zapewniać komunikację z wykorzystaniem bezpiecznych protokołów transmisji danych, a także mechanizmy uwierzytelniania i autoryzacji, umożliwiające kontrolę dostępu do kolejek i operacji.
- Wysoka dostępność oraz odtwarzanie po awarii – broker powinien wspierać mechanizmy zapewniające nieprzerwane działanie, takie jak replikacja danych, strategie przywracania po awarii oraz możliwość tworzenia kopii zapasowych.
- Wysoka wydajność przetwarzania komunikatów – broker powinien oferować mechanizmy wysokiej przepustowości przetwarzania wiadomości, przy jednoczesnym optymalnym wykorzystaniu zasobów systemowych (CPU/RAM).
W kolejnych sekcjach przeanalizujemy te obszary w kontekście Apache Kafka, omawiając jej możliwości oraz elementy, na które warto zwrócić szczególną uwagę, aby uniknąć problemów.
Wdrażanie i konfiguracja Kafka
Apache Kafka oferuje różne opcje instalacji. W naszych projektach najczęściej wykorzystujemy wdrożenia na klastrach Kubernetes lub RedHat OpenShift, ponieważ zapewniają one wysoki poziom dostępności i bezpieczeństwa (szczegółowe omówienie tych aspektów wykracza poza zakres tego artykułu).
Jednym z popularnych sposobów instalacji Apache Kafka na OpenShift jest Strimzi (strimzi.io), działające zgodnie ze wzorcem Operator (Operator Pattern). Strimzi wprowadza zestaw dedykowanych zasobów (Custom Resource Definitions – CRD), umożliwiających opisanie instalacji klastra Kafka, Kafka Connect, konektorów, definiowanie topiców oraz zarządzanie dostępami.
Jedną z głównych zalet Strimzi jest znaczące uproszczenie instalacji całego ekosystemu Apache Kafka, który – jak omówiliśmy w sekcji dotyczącej architektury – składa się z wielu komponentów.
W poniższych przykładach do definiowania zasobów klastra OpenShift wykorzystujemy szablony Helm (helm.sh).
Instalacja klastra Apache Kafka
Podstawowym CRD jest CRD typu Kafka, który pozwala na instalację klastra Kafka:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: {{ include "broker.fullname" . }}
labels:
{{- include "broker.labels" . | nindent 4 }}
spec:
kafka:
resources: (1)
requests:
cpu: {{ .Values.kafka.resources.requests.cpu }}
memory: {{ .Values.kafka.resources.requests.memory }}
limits:
cpu: {{ .Values.kafka.resources.limits.cpu }}
memory: {{ .Values.kafka.resources.limits.memory }}
version: 3.4.0
replicas: {{ .Values.kafka.replicas}} (2)
…
W (1) określamy zasoby obliczeniowe dla brokerów Kafka, takie jak żądane CPU/RAM oraz limity CPU i RAM.
W (2) definiujemy liczbę brokerów, które będą tworzyć klaster Apache Kafka.
W tym samym CRD możemy również określić parametry instalacji Zookeepera.
zookeeper:
resources: (1)
requests:
cpu: {{ .Values.zookeeper.resources.requests.cpu }}
memory: {{ .Values.zookeeper.resources.requests.memory }}
limits:
cpu: {{ .Values.zookeeper.resources.limits.cpu }}
memory: {{ .Values.zookeeper.resources.limits.memory }}
replicas: {{ .Values.zookeeper.replicas }} (2)
W (1) określamy zasoby CPU/RAM przeznaczone dla Zookeepera, a w (2) liczbę jego instancji.
Dodatkowo, w tym samym CRD możemy skonfigurować parametry dyskowe dla Apache Kafka oraz szczegółowe ustawienia konfiguracyjne:
storage: (1)
type: jbod
volumes:
- id: 0
type: persistent-claim
size: {{ .Values.kafka.storage.size }}
deleteClaim: true
class: {{ .Values.kafka.storage.class }}
- id: 1
type: persistent-claim
size: {{ .Values.kafka.storage.size }}
deleteClaim: true
class: {{ .Values.kafka.storage.class }}
config: (2)
message.max.bytes:{{ .Values.kafka.config.messageMaxBytes }} (3)
num.partitions:{{.Values.kafka.config.defaultNumPartitions }}(4)
log.retention.hours:{{.Values.kafka.config.logRetentionHours}}(5)
num.network.threads: {{.Values.kafka.config.networkThreads }} (6)
num.io.threads: {{.Values.kafka.config.ioThreads }} (7)
W (1) znajduje się definicja storage dla tworzonego klastra Apache Kafka.
W (2) określamy szczegółowe parametry konfiguracyjne brokera. W powyższym przykładzie zdefiniowano kilka podstawowych parametrów, takich jak:
• (3) maksymalny rozmiar wiadomości,
• (4) domyślna liczba partycji,
• (5) domyślna retencja dla topiców,
• (6) liczba wątków sieciowych,
• (7) liczba wątków I/O.
Po załadowaniu powyższej konfiguracji do klastra Kubernetes lub OpenShift i jej przetworzeniu przez operatora Strimzi, uzyskamy w pełni funkcjonalny klaster Apache Kafka obsługiwany przez Zookeepera. Jego działanie można zweryfikować za pomocą odpowiednich narzędzi:

Po wylistowaniu POD’ów zobaczymy zarówno broker’y jak i Zookeeper:


Kolejnym elementem koniecznym do instalacji jest Kafka Connect co możemy osiągnąć przy pomocy innego CRD dostarczanego przez Strimzi jakim jest KafkaConnect:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: connect-cluster-{{ include "broker.fullname" . }}
annotations:
strimzi.io/use-connector-resources: "true"
spec:
image:{{ .Values.kafkaConnect.image.repository}}:{{ .Values.kafkaConnect.image.tag}}
replicas: {{ .Values.kafkaConnect.replicas}} (1)
bootstrapServers: {{ include "broker.fullname" . }}-kafka-bootstrap:9093 (2)
W punkcie (1) definiujemy liczbę instancji wchodzących w skład klastra Kafka Connect, (2) określa namiar na klaster Apache Kafka. CRD KafkaConnect pozwala tez określić inne elementy takie jak bezpieczeństwo, storage, zasoby, parametry konfiguracyjne Zookeeper.
Po wgraniu tego CRD na klaster OpenShift dostaniemy funkcjonalny klaster KafkaConnect co można sprawdzić następującym poleceniem:

W ten sposób sprawnie i szybko zainstalowaliśmy klaster Apache Kafka oraz Kafka Connect. Ostatnim krokiem jest wdrożenie przykładowego topicu oraz przykładowego konektora.
Zacznijmy od definicji topicu, do której Strimzi dostarcza dedykowane CRD – KafkaTopic:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: {{ .Values.kafkaTopics.file.data.name }} (1)
labels:
strimzi.io/cluster: {{ .Values.kafkaTopics.cluster }}
spec:
partitions: {{.Values.kafkaTopics.file.data.partitions }} (2)
replicas: {{.Values.kafkaTopics.file.data.replicas }} (3)
config:
retention.ms:{{.Values.kafkaTopics.file.data.config.retention}} (4)
Ten prosty plik pozwala określić:
• (1) Nazwę topicu.
• (2) Liczbę partycji topicu – jeśli nie zostanie podana, Kafka użyje domyślnej wartości skonfigurowanej na poziomie brokera (zgodnie z opisem CRD dla klastra Kafka).
• (3) Liczbę replik topicu – określa, ile kopii danych powinno być przechowywanych w klastrze.
• (4) Retencję topicu – czas przechowywania danych przed ich usunięciem. Wiadomości starsze niż określona wartość będą usuwane.
Parametr retencji jest kluczowy w kontekście zarządzania przestrzenią dyskową klastra Kafka. Różne topici mogą mieć ustawione różne wartości w zależności od potrzeb – topicom o większym znaczeniu biznesowym można przypisać dłuższą retencję.
Teraz przygotujmy przykładową definicję konektora, korzystając z CRD KafkaConnector.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: jmssourceconnector-{{ $connector.name }}
labels:
strimzi.io/cluster: {{ $.Values.kafkaConnectors.kccluster }}
spec:
class: com.datamountaineer.streamreactor.connect.jms.source.JMSSourceConnector (1)
tasksMax: {{ .Values.connector.tasksMax }} (2)
autoRestart:
enabled: {{ $.Values.connector.autoRestart }} (3)
config: (4)
connect.jms.connection.factory: {{ .Values.connector.connectionFactory }}
connect.jms.destination.selector: {{ .Values.connector.selector }}
connect.jms.initial.context.factory:{{.Values.connector.contextFactoryClass }}
connect.jms.kcql: INSERT INTO test_topic SELECT * FROM {{ .Values .connector.queue }} WITHTYPE QUEUE
connect.jms.queues: {{ .Values.connector.queue }}
connect.jms.url: {{ .Values.connector.urls }}
connect.progess.enabled: {{ .Values.connector.progessEnabled }}
connect.jms.scale.type: {{ .Values.scaleType }}
connect.jms.username: {{ .Values.username }}
connect.jms.password: {{ .Values.password }}
Ten plik definiuje konektor JMS typu source, który odpowiada za odczyt danych z kolejki JMS i przekazanie ich do topicu Kafka:
- (1) Klasa implementująca konektor – określa komponent, który zostanie uruchomiony do odbierania wiadomości z serwera JMS. Każdy konektor ma swoją implementację w postaci plików JAR dostarczanych przez producenta konektora. Pliki te muszą znajdować się na klastrze Kafka Connect, aby mogły być używane w czasie działania (runtime).
- (2) Liczba zadań konektora – określa liczbę instancji zadań uruchomionych w klastrze Kafka Connect. Dzięki temu parametrowi można kontrolować liczbę równolegle działających instancji, co wpływa na przepustowość przetwarzania danych.
- (3) Parametry konfiguracyjne konektora – specyficzne dla danej implementacji. Powinny być ustawiane zgodnie z dokumentacją dostarczoną przez producenta konektora. W przedstawionym przykładzie są to parametry wymagane do podłączenia się do zewnętrznego serwera JMS.
W ten sposób zakończyliśmy proces instalacji klastra Apache Kafka i Kafka Connect, a także wdrożenie przykładowego topicu oraz konektora.
Jak widać, Kafka oferuje wiele możliwości konfiguracyjnych, a Strimzi umożliwia ich definiowanie za pomocą dedykowanych CRD. Wykorzystanie Helm pozwala na parametryzację tych CRD (poprzez dedykowane pliki Values), co umożliwia utrzymywanie wielu konfiguracji, np. dla środowisk deweloperskich, testowych i produkcyjnych.
Jedną z kluczowych zalet takiego podejścia do zarządzania instalacją i konfiguracją klastra Kafka jest możliwość przechowywania plików konfiguracyjnych (szablonów) – są to pliki YAML – w systemie kontroli wersji w dedykowanym repozytorium. Dzięki temu można łatwo audytować zmiany i śledzić historię modyfikacji.
Taka konfiguracja może być następnie wdrażana na środowiska przy użyciu pipeline’ów w narzędziach takich jak GitLab czy Jenkins. Dodatkowo możliwe jest wykorzystanie systemów automatycznej synchronizacji, np. ArgoCD (https://argo-cd.readthedocs.io/en/stable/), które monitorują repozytorium pod kątem zmian i automatycznie propagują je na środowiska docelowe.
Po omówieniu procesu wdrażania i konfiguracji Kafki przejdźmy teraz do kwestii bezpieczeństwa.
Bezpieczeństwo systemu komunikacji zdarzeniowej
Każdy system przeznaczony do komunikacji zdarzeniowej powinien zapewniać bezpieczeństwo przesyłanych danych, obejmujące szyfrowanie, uwierzytelnianie i autoryzację. W tym zakresie Apache Kafka, zgodnie z oficjalną dokumentacją, oferuje następujące mechanizmy zabezpieczeń:
- Uwierzytelnianie połączeń klienckich do brokera z użyciem protokołów takich jak SSL lub SASL,
- Uwierzytelnianie komunikacji między brokerem a Zookeeperem,
- Szyfrowanie przesyłanych danych – zarówno między klientami a brokerem, jak i pomiędzy brokerami w ramach replikacji,
- Autoryzację operacji wykonywanych przez klientów w celu kontroli dostępu do tematów i zasobów.
Dostosowanie Apache Kafka do spełnienia wymogów bezpieczeństwa wymaga konfiguracji wielu parametrów. Przykładowo, konieczne jest skonfigurowanie zabezpieczonego listenera:
listeners=BROKER://localhost:9092 listener.security.protocol.map=BROKER:SASL_SSL,CONTROLLER:SASL_SSL
oraz wygenerowanie kluczy SSL przy pomocy narzędzi takich jak keytool. Proces ten wymaga szczególnej uwagi i koncentracji, ale zdecydowanie jest to konfiguracja którą warto wykonać w celu zapewnienia pełnego bezpieczeństwa przesyłanych danych.
Jeśli Kafka jest wdrażana na klastrze Kubernetes lub OpenShift i korzysta z Strimzi, konfiguracja uwierzytelniania staje się prostsza. Strimzi automatyzuje wiele procesów, udostępniając odpowiednie wpisy w plikach CR (Custom Resource), a także dodatkowe definicje CRD (Custom Resource Definitions), które upraszczają zarządzanie bezpieczeństwem.
Rozpocznijmy od konfiguracji uwierzytelniania dla brokera – w pliku definiującym klaster Kafka dostępne są następujące opcje:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: {{ include "broker.fullname" . }}
labels:
{{- include "broker.labels" . | nindent 4 }}
spec:
kafka:
…
listeners: (1)
- name: tls (2)
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external (3)
port: 9094
type: route
tls: true
authentication:
type: tls
…
- (1) Definicja listenerów.
- (2) Listener wewnętrzny (dla klastra OpenShift) działający na porcie 9093, z włączonym TLS oraz uwierzytelnianiem opartym na certyfikacie.
- (3) Zewnętrzny port 9094 (udostępniony za pomocą route OpenShift) z włączonym TLS, ale bez uwierzytelniania certyfikatowego.
Po załadowaniu tej konfiguracji operator Strimzi automatycznie wygeneruje odpowiednie secrety OpenShift, które będą wykorzystywane do zarządzania uwierzytelnianiem i szyfrowaniem komunikacji:
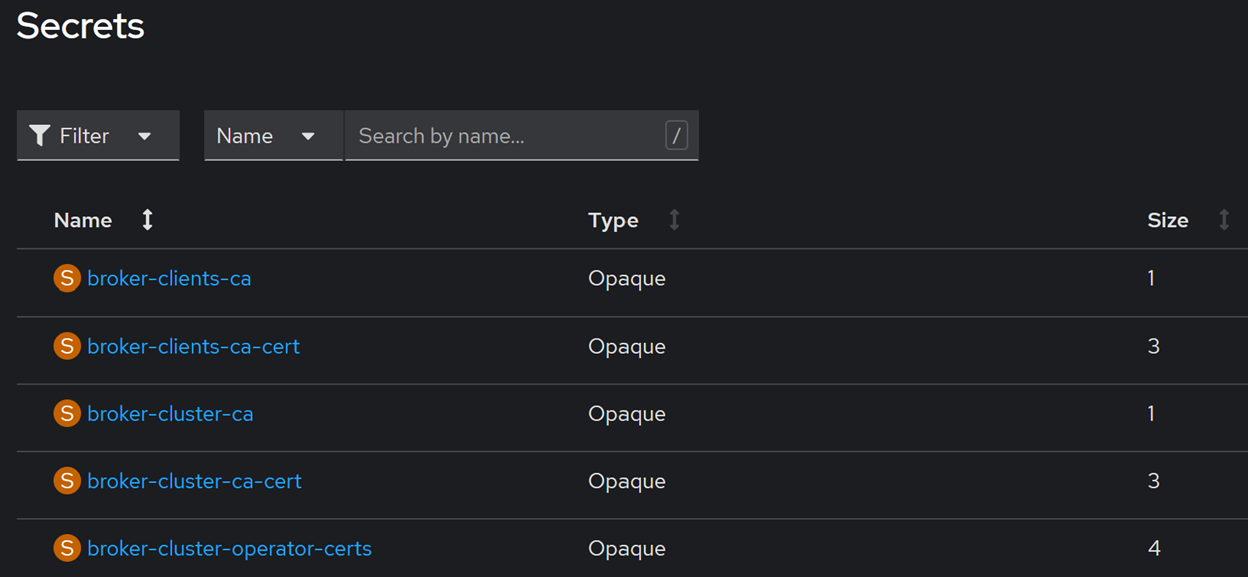
Jeśli teraz spojrzymy na wcześniej przygotowany i wdrożony klaster Kafka Connect, zauważymy, że nie będzie on mógł połączyć się z brokerem Kafka. Aby przywrócić komunikację między tymi komponentami, konieczne jest dostosowanie konfiguracji Kafka Connect, uwzględniając aspekty związane z bezpieczeństwem.
W tym celu należy wprowadzić odpowiednie zmiany w pliku CR (Custom Resource) dla KafkaConnect:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: connect-cluster-{{ include "broker.fullname" . }}
spec:
rack:
…
bootstrapServers:{{include "broker.fullname" .}}-kafka-bootstrap:9093
authentication: (1)
type: tls
certificateAndKey:
secretName: kafka-connect-tls-user
certificate: user.crt
key: user.key
tls: (2)
trustedCertificates:
- secretName: {{ include "broker.fullname" . }}-cluster-ca-cert
certificate: ca.crt
- (1) W tym miejscu definiujemy sposób, w jaki Kafka Connect będzie się łączyć i uwierzytelniać w brokerze Kafka. Wskazujemy użycie protokołu TLS oraz informujemy, że Kafka Connect ma się „przedstawić” za pomocą certyfikatu.
- (2) Tutaj konfigurujemy, jak Kafka Connect będzie “ufać” certyfikatowi, którym broker Kafka uwierzytelnia się podczas nawiązywania połączenia. Widać, że odnosi się on do secretu OpenShift, który operator Strimzi wygenerował w poprzednim kroku.
Pozostaje jednak kluczowe pytanie: skąd Kafka Connect w miejscu oznaczonym (1) weźmie certyfikat? Przecież nigdzie nie definiowaliśmy secretu kafka-connect-tls-user.
Odpowiedź jest prosta – ten certyfikat reprezentuje użytkownika lub aplikację, która łączy się z brokerem Kafka. Strimzi dostarcza w tym celu dedykowany CRD o nazwie KafkaUser, który pozwala na zdefiniowanie takiego użytkownika:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaUser
metadata:
name: kafka-connect-tls-user
labels:
strimzi.io/cluster: {{ include "broker.fullname" . }}
spec:
authentication: (1)
type: tls
authorization:(2)
type: simple
acls:
- resource: (3)
type: topic (3.1)
name: event-data (3.2)
patternType: literal (3.3)
operations: (3.4)
- Create
- Describe
- DescribeConfigs
- Read
- Write
host: "*" (3.5)
# consumer group aws s3 sink connector
- resource:
type: group (4)
name: connect-sinkconnector
patternType: literal
operations:
- Create
- Describe
- Read
- Write
host: "*"
Przyjrzyjmy się zawartości tego pliku:
- (1) Definiujemy uwierzytelnianie TLS dla tworzonego użytkownika.
- (2) Określamy uprawnienia użytkownika – jest to lista elementów definiujących dostęp do zasobów.
- (3) Definiujemy pierwszy zasób typu topic:
- (3.1) Określamy typ zasobu jako topic.
- (3.2) Ustawiamy jego nazwę.
- (3.3) Wskazujemy, że nazwa ma być traktowana literalnie – można również użyć wartości prefix, co pozwala na nadanie uprawnień do wszystkich zasobów, których nazwa zaczyna się od określonego ciągu znaków.
- (3.4) Wymieniamy operacje, do których użytkownik ma prawo dostępu.
- (3.5) Określamy adres/host, z którego użytkownik może się łączyć.
- (4) Definiujemy zasób innego typu – grupę konsumentów o określonej nazwie oraz listę dozwolonych operacji dla tej grupy.
Po załadowaniu tej definicji operator Strimzi automatycznie wygeneruje odpowiedni secret, który Kafka Connect wykorzysta do uwierzytelnienia w brokerze i który będzie zrozumiały dla brokera:
Jeśli aplikacja (KafkaUser) korzystająca z takiego certyfikatu spróbuje wykonać na brokerze operację niedozwoloną (czyli taką, której nie uwzględniliśmy w definicji KafkaUser), broker automatycznie ją zablokuje. W logach zobaczymy wtedy komunikat o błędzie:
2024-10-02 13:42:21,932 INFO Principal = User:CN=kafka-connect-tls-user is Denied Operation = Describe from host = 10.253.23.147 on resource = Cluster:LITERAL:kafka-cluster for request = ListPartitionReassignments with resourceRefCount = 1
Powyższy błąd wskazuje, że użytkownik kafka-connect-tls-user nie posiada uprawnień do pobierania informacji o klastrze. Jest to oczekiwane zachowanie, ponieważ nie nadaliśmy mu takiego dostępu w konfiguracji.
Aby usunąć ten błąd, musimy dodać odpowiednie uprawnienie do pliku konfiguracyjnego:
- resource: type: cluster operations: - Describe host: "*"
W przedstawionym przykładzie pojawia się nowy typ zasobu reprezentujący klaster Kafka.
Jak widać, Apache Kafka oferuje szerokie możliwości konfiguracyjne w zakresie bezpieczeństwa – od uwierzytelniania, przez szyfrowanie, aż po autoryzację. Jeśli korzystamy z Strimzi, konfiguracja tych mechanizmów staje się znacznie prostsza, ponieważ wiele elementów jest generowanych automatycznie przez operatora Strimzi.
Potwierdziliśmy zatem, że pod względem bezpieczeństwa Apache Kafka to rozwiązanie klasy enterprise, które spełni wymagania nawet najbardziej rygorystycznych departamentów bezpieczeństwa.
Przejdźmy teraz do analizy wysokiej dostępności Kafki i metod zapewnienia jej niezawodności.
Wysoka dostępność oraz odtwarzanie po awarii
Systemy komunikacji zdarzeniowej odpowiadają za przesyłanie komunikatów między wieloma systemami i usługami. Im więcej komponentów polega na takiej komunikacji, tym większe znaczenie ma rola brokera w całym przepływie informacji.
Co jednak stanie się w przypadku awarii brokera? Czy może on stać się pojedynczym punktem awarii (Single Point of Failure, SPOF)? Odpowiedź brzmi: tak – jeśli system jest źle rozmieszczony i skonfigurowany, może stać się SPOF.
Jak zatem Apache Kafka radzi sobie z tym wyzwaniem?
Podstawowym mechanizmem zapewniającym wysoką dostępność w Kafce jest replikacja. Replikacja oznacza, że dane z partycji topicu są przechowywane na różnych węzłach klastra. W przypadku awarii jednego z węzłów jego rolę mogą przejąć inne węzły, ponieważ dane są replikowane.
Poniższy diagram ilustruje ten proces:
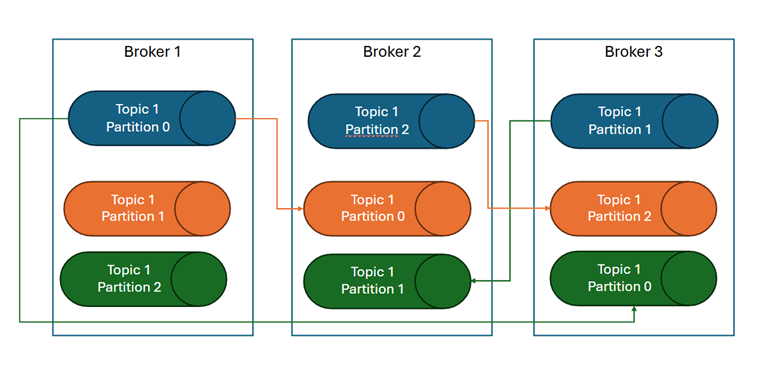
Klaster Kafka składa się z trzech brokerów. Na poniższym diagramie kolorem niebieskim zaznaczono liderów partycji. Przykładowo, Broker 1 pełni rolę lidera partycji 0 w topicu 1 i odpowiada za replikację danych tej partycji na inne węzły klastra:
- Broker 2 jest pierwszą repliką partycji 0 w topicu 1 (kolor pomarańczowy),
- Broker 3 jest drugą repliką partycji 0 w topicu 1 (kolor zielony).
Węzły Broker 2 i Broker 3 są nazywane in-sync replicas (ISR), czyli synchronizowanymi replikami. W przypadku awarii Brokera 1, jeden z brokerów in-sync zostanie automatycznie wybrany nowym liderem partycji 0 dla topicu 1, co pozwoli klientom na nieprzerwane korzystanie z topicu. Dzięki temu mechanizmowi Kafka zapewnia odporność na awarie.
Dodatkowo, jeśli Kafka jest wdrażana na klastrze OpenShift, który jest rozmieszczony w podziale na dwa centra danych (głównym – Data Center i zapasowym – Disaster Recovery Center), można wymusić odpowiednie rozmieszczenie brokerów, aby zwiększyć dostępność systemu. Węzły trafiają w tym wypadku również do zapasowego centrum co zwiększa dostępność naszej instalacji. W tym celu warto skorzystać z konfiguracji przynależności (affinity), która umożliwia kontrolę nad tym, gdzie uruchamiane są poszczególne węzły klastra.
affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: …
Kolejnym kluczowym elementem zapewnienia niezawodność jest możliwość odtworzenia systemu po awarii oraz tworzenie kopii zapasowych. W tym zakresie dostępnych jest kilka metod:
- Opcja 1:
Część osób wykorzystuje narzędzie Kafka Mirror Maker, które pozwala na replikację danych między klastrami Kafka. W tym modelu mamy klaster podstawowy, oraz klaster zapasowy – rozmieszczony w innym miejscu. MirrorMaker jest używany do synchronizacji danych między tymi klastrami. W przypadku awarii klastra podstawowego, ruch zostanie przekierowywany do klastra zapasowego.
- Opcja 2:
W przypadku instalacji na klastrze OpenShift, gdy dyski klastra Kafka są dostarczane przez OpenShift, pojawia się możliwość tworzenia ich kopii zapasowych (ang. Persistent Volume Claim) za pomocą tzw. snapshotów. Jednym z narzędzi umożliwiających to działanie jest Commvault. W jednym z projektów Inteca sprawdzaliśmy, czy możliwe jest wykonanie kopii zapasowej PVC klastra Kafka bez konieczności wyłączania jego węzłów. Sama kopia zapasowa przebiegła bez problemów, jednak odtworzenie danych okazało się problematyczne i nie zawsze kończyło się powodzeniem. Głównym wyzwaniem była spójność danych po przywróceniu.
Aby skutecznie korzystać z takich narzędzi do tworzenia kopii zapasowych, warto rozważyć wyłączenie klastra Kafka na czas wykonywania snapshotu. Choć wiąże się to z krótkotrwałą niedostępnością systemu, może znacząco zwiększyć niezawodność procesu przywracania danych.
- Opcja 3:
Opcją która jest często wykorzystywana w przypadku tworzenia kopii zapasowej Apache Kafka jest tworzenie kopii zapasowej poprzez wysłanie danych do S3. W tym podejściu w ramach Kafka Connect używany jest konektor S3 typu sink, który pobiera dane z topiców i wysyła do S3 (konektor S3 source jest wyłączony):
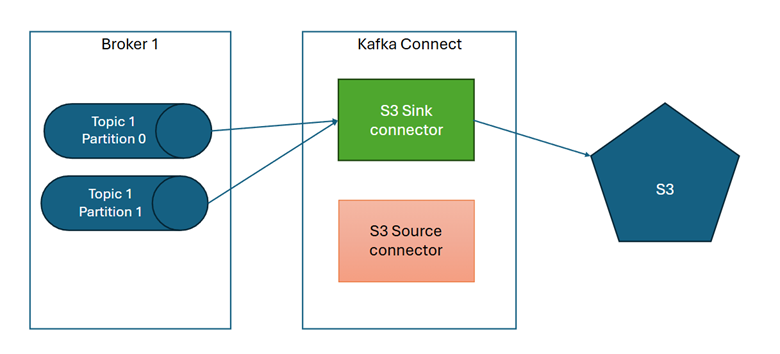
W momencie przywrócenia działania systemu po awarii, konektory zmieniają swój stan i następuje odczytanie danych z kopii zapasowej (konektor sink jest wyłączony a source włączony):
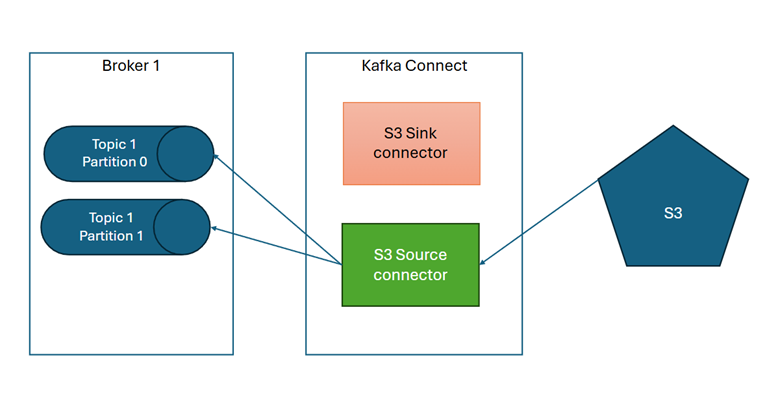
Po przywróceniu danych z kopii zapasowej konektory wracają do ustawienia pierwotnego. Należy tutaj zaznaczyć że zmiany stanów konektorów w momencie odtwarzania z backupu oraz po odtworzeniu są operacjami manualnymi, czynnościami administracyjnymi.
Opisane wyżej podejście to często wykorzystywane rozwiązanie do tworzenia kopii zapasowych dla Apache Kafka. Należy jednak zwrócić uwagę na jeden istotny fakt a mianowicie odpowiednie odtworzenie danych i przywrócenie offsetów dla grup konsumentów:
- W zakresie odtworzenia danych konieczne jest zapewnienie aby dane trafiły na odpowiednie partycje w odpowiedniej kolejności, jeśli się to nie uda to grupy konsumentów mogą zacząć przetwarzać dane już raz przeprocesowane albo (w szczególnym przypadku) części danych w ogóle nie przeprocesować,
- Drugim ważnym aspektem jest zachowanie informacji o tym gdzie dana konsumer grupa skończyła przetwarzanie tzn. zachowanie informacji o offsetach przetwarzania poszczególnych partycji topicu.
Przedstawimy to na przykładzie:
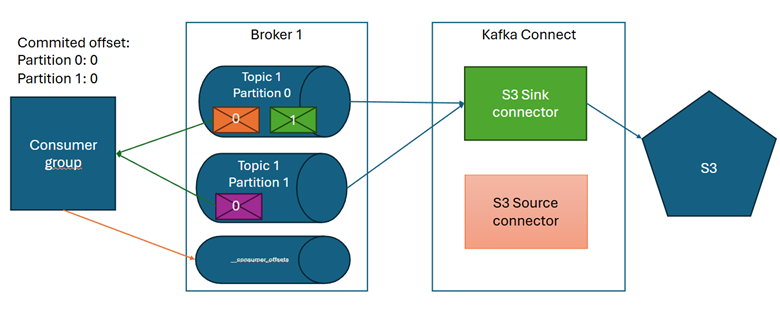
Konsument odczytuje dane z topicu 1. Z partycji 0 pobrał i przetworzył wiadomość 0, podobnie jak dla partycji 1. Po przetworzeniu konsument informuje broker że te wiadomości są już przetworzone i ta informacja jest zapisywana w specjalnym, wewnętrznym topicu Kafka o nazwie __consumer_offsets. Wiadomość 1 z partycji 0 nie została potwierdzona tzn. offset grupy dla tej partycji jest mniejszy niż offset tej wiadomości.
Jeśli po awarii odczytamy dane z kopii zapasowej, a podczas ich odtwarzania wiadomości zamienią swoje partycje lub kolejność, zapisane informacje o tym, gdzie dany konsument zakończył przetwarzanie, staną się bezużyteczne. Co więcej, ich użycie może prowadzić do błędów.
Na przykład, jeśli po przywróceniu partycja 1 zawiera zarówno wiadomość fioletową, jak i pomarańczową, a partycja 0 jedynie wiadomość zieloną, mogą wystąpić następujące problemy:
- Wiadomość zielona nigdy nie zostanie przetworzona, ponieważ offset dla tej partycji wskazuje, że wiadomość z offsetem 0 została już przeprocesowana – choć w rzeczywistości jeszcze nie była.
- Wiadomość pomarańczowa, która trafiła do partycji 1 zamiast do partycji 0, może mieć offset 1. W kontekście zapisanego offsetu dla tej partycji oznacza to, że musi zostać przetworzona – mimo że już wcześniej była przeprocesowana.
Dlatego niezwykle istotne jest, aby podczas odtwarzania zachować zarówno poprawne przypisanie wiadomości do partycji, jak i ich kolejność. Kluczowe jest również odwzorowanie stanu przetwarzania poszczególnych grup konsumentów, czyli ich offsetów.
Jakich konektorów można użyć do implementacji takiej kopii zapasowej?
Confluent dostarcza odpowiednie konektory, np. Confluent S3 Source Connector. Należy jednak pamiętać, że wymagają one licencji.
Alternatywą są opensource’owe konektory Apache Camel S3 Sink oraz Source, jednak mają one pewne ograniczenia implementacyjne:
- Nie zapisują informacji o partycji, z której pochodzi wiadomość.
- Każdą wiadomość zapisują jako osobny obiekt w S3.
Z tego względu ich produkcyjne użycie wymaga dostosowania, np. poprzez implementację dedykowanego transformatora wiadomości dla konektora sink (ang. Single Message Transformations), który będzie propagować informację o partycji i offsecie do S3. Oraz drugiego transformatora dla konektora source, który użyje informacji o partycji i offsecie, zapisanych w S3 do poprawnego przywrócenia wiadomości.
Omówiliśmy elementy związane z wysoką dostępnością oraz kopią zapasową. Przejdźmy do kwestii monitorowania naszej instalacji Kafki na środowisku produkcyjnym.
Monitorowanie działania Kafka
Dla każdego systemu komunikacji zdarzeniowej istotne jest monitorowanie jego działania produkcyjnego aby chronić się przed takimi problemami jak utrata danych, przestoje w przetwarzaniu czy niewystarczająca wydajność przetwarzania. Apache Kafka z racji swojej architektury i sposobu działania wymaga monitorowania stanu klastra, utylizacji zasobów, replikacji, konektorów oraz wydajności przetwarzania.
Apache Kafka potrafi wystawić te informacje do Prometheus (https://prometheus.io/), skąd te dane można pobrać i wizualizować na przykład przy użyciu Grafana (https://grafana.com/).
Aby zrealizować taki monitoring, w przypadku instalacji klastra Kafka na OpenShift, można zdefiniować odpowiedni PodMonitor czyli byt pochodzący z Prometheus Operator, który jest wbudowany w platformę OpenShift:
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: kafka-resources-metrics
labels:
app: strimzi
spec:
selector:
matchExpressions:
- key: "strimzi.io/kind"
operator: In
values: ["Kafka", "KafkaConnect", "KafkaMirrorMaker", "KafkaMirrorMaker2"]
namespaceSelector:
matchNames:
- {{ .Release.Namespace }}
podMetricsEndpoints:
- path: /metrics
port: tcp-prometheus
interval: 1m
relabelings:
- separator: ;
regex: __meta_kubernetes_pod_label_(strimzi_io_.+)
replacement: $1
action: labelmap
…
Po wgraniu tej definicji i skonfigurowaniu Grafana otrzymamy następujący widok:
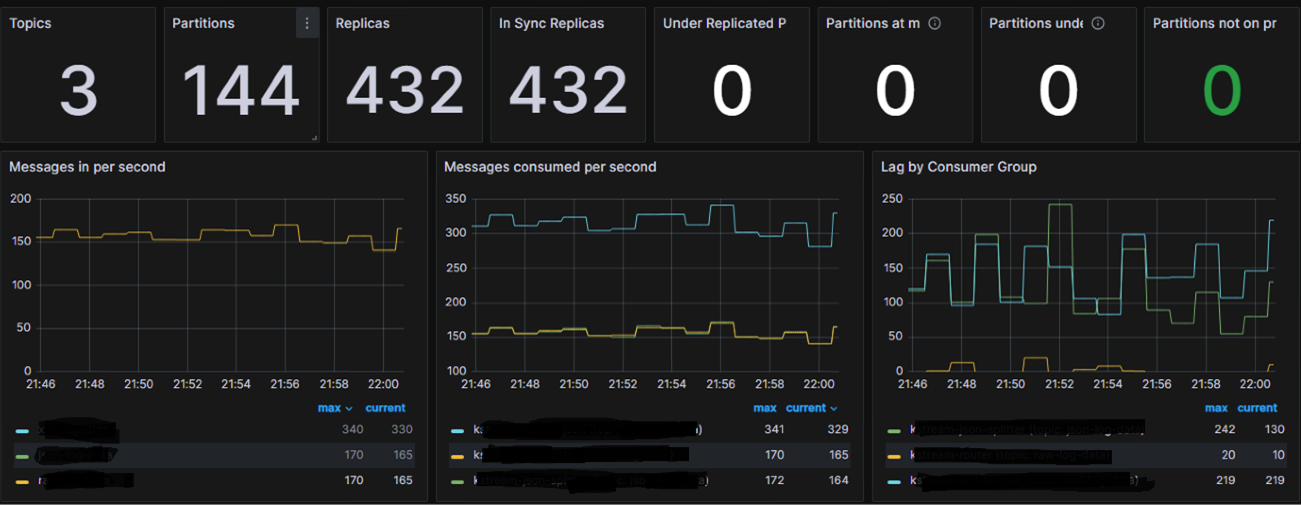
Znajdują się tu takie informacje jak:
- Liczba replik,
- Liczba In Sync Replicas,
- Szczegółowe dane na temat partycji
- Liczbę wiadomości publikowane na sekundę,
- Liczbę wiadomości procesowanych przez konsument grupy na sekundę
- Lag, czyli różnicę między aktualnym offsetem wiadomości na partycjach topicu a offsetem przetworzonym przez grupę konsumentów. Im większy lag tym gorzej, ponieważ może to oznaczać że konsument grupa nie nadąża z procesowaniem wiadomości.
Dodatkowo można zdefiniować również alerty w oparciu o Prometheus Alert Manager lub Grafana Alerting, dzięki czemu możliwe będzie otrzymywanie powiadomień o problemach.
Kolejnym narzędzie wartym polecenia w tym obszarze jest Redpanda Console. To narzędzie pozwala na weryfikację stanu klastra, konektorów, konsumer grup oraz topiców:
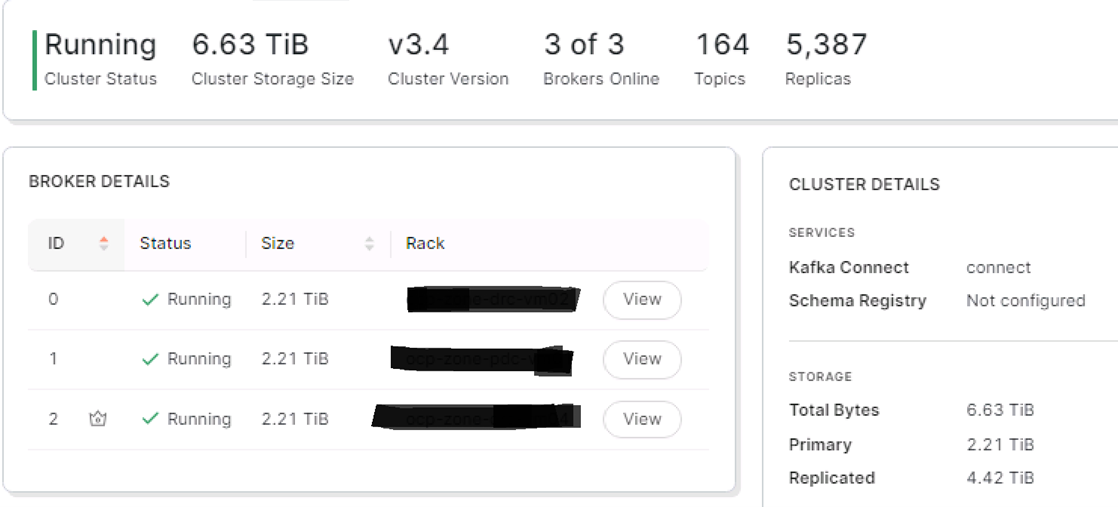
Dodatkowo narzędzie to pozwala na wykonywanie operacji aktywnych jak na przykład restart konektora, usunięcie wiadomości z topicu, usunięcie topicu. Wszystkie te funkcjonalności są przydatne przy codziennym utrzymaniu Kafki i wykonywaniu operacji administracyjnych.
Wyposażeni w narzędzia monitorujące, możemy przejść do ostatniego tematu jakim jest wysoka wydajność przetwarzania.
Wysoka wydajność przetwarzania
Systemy komunikacji zdarzeniowej muszą odznaczać się wysoką wydajnością przetwarzania danych. Integrują one i przesyłają wiadomości między różnymi systemami i zbyt wolne przetwarzanie komunikatów może prowadzić do poważnych problemów zwłaszcza w rozwiązaniach zbliżonych do rozwiązań czasu rzeczywistego.
Jak już wspomniałem w punkcie dotyczącym architektury, ważnym elementem zapewnienia wydajności przetwarzania jest odpowiednie dobranie liczby partycji dla topiców. Liczba partycji określa nam maksymalną liczbę wątków procesujących równolegle dane z danego topicu. Ale to nie jedyny parametr o którym należy pamiętać.
Kafka procesuje ogromne ilości danych które są nieustanie przesyłane między klientami a brokerami oraz pomiędzy brokerami w ramach procesu replikacji. Dlatego istotne jest aby narzuty na ruch sieciowy nie powodowały problemu z wydajnością. Wpływ narzutów komunikacji sieciowej ma ogromny wpływ na wydajność całego przetwarzania. Apache Kafka dostarcza nam w tym zakresie kilku parametrów:
- Kompresja (compression.type) – pozwala na włączenie kompresji ze strony producenta np. konektora lub aplikacji streamowej. Dzięki kompresji możemy znacząco zmniejszyć rozmiar przesyłanych przez sieć danych. Kafka wspiera następujące typy kompresji: none, gzip, snappy, lz4, zstd. Domyślnie włączona jest kompresja typu ‘none’ czyli brak kompresji. Nie jest to zalecane ustawienie dla wdrożeń produkcyjnych chyba, że zachodzą uzasadnione powody dla takiej konfiguracji. Kompresja jest włączana po stronie producenta Kafki. Konsumenci nie wymagają specjalnej konfiguracji a proces dekompresji realizowany po stronie konsumenta zachodzi automatycznie za sprawą bibliotek klienckich Kafki. Włączenie kompresji wprowadza narzut na przeprowadzenie tego procesu po stronie producenta i konsumenta ale generalnie, mimo tego narzutu, znacząco zwiększa przepustowość producenta,
- Rozmiar batch (batch.size) – kolejny parametr dedykowany dla producenta Kafka. Określa w jakich ‘paczkach’ producent wysyła wiadomości a jego domyślna wartość do 16KB. Oznacza to, że jeśli nasze wiadomości mają rozmiar większy od 16KB to każda z tych wiadomości będzie wysyłana oddzielnie co przekłada się na negatywny wpływ narzutów sieciowych na przepustowość. Lepiej wysyłać rzadziej a więcej, dlatego warto rozważyć dostosowanie wartości tego parametru do rozmiaru naszych wiadomości,
- Czas opóźnienia/’marudzenia’ (linger.ms) – również parametr dedykowany dla producentów Kafka i ściśle powiązany z parametrem batch.size. Parametr ten określa ile czasu producent czeka na wypełnienie się batch. Jeśli batch wypełni się wiadomościami przed upływem tego czasu to taki batch jest wysyłany. Jeśli brach nie jest wypełniony wiadomościami ale upłynął czas linger to również batch jest wysyłany. Domyślna wartość tego parametru to 0ms co oznacza że wiadomości wysłane są natychmiast czyli znów wysyłamy bardzo często a narzuty sieciowe mogą mieć negatywny wpływ na przepustowość naszego rozwiązania.
Poniżej przykład dla jednego z realizowanych systemów:
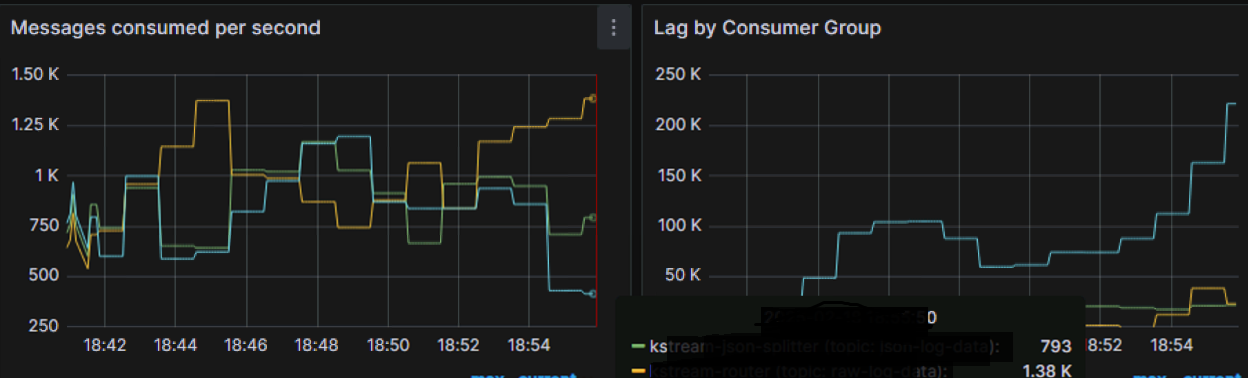
Jak widać na załączonych wykresach system wykorzystuje 3 aplikacje streamowe. Jedna z tych aplikacji (wykres żółty) przetwarza około 1250 wiadomości na sekundę, aplikacja zielona przetwarza 750 wiadomości, a aplikacja niebieska najmniej – poniżej 500 wiadomości na sekundę. Skutkiem tego aplikacja niebieska ma największy lag (co widać na wykresie po prawej), który nieustannie rośnie co może skutkować zbyt późnym dostarczeniem danych do systemów docelowych.
Po zmianie opisanych wyżej parametrów:
- type=lz4 dla wszystkich producentów,
- size=128KB dla wszystkich producentów,
- ms=100ms dla wszystkich producentów,
otrzymaliśmy następujące rezultaty:
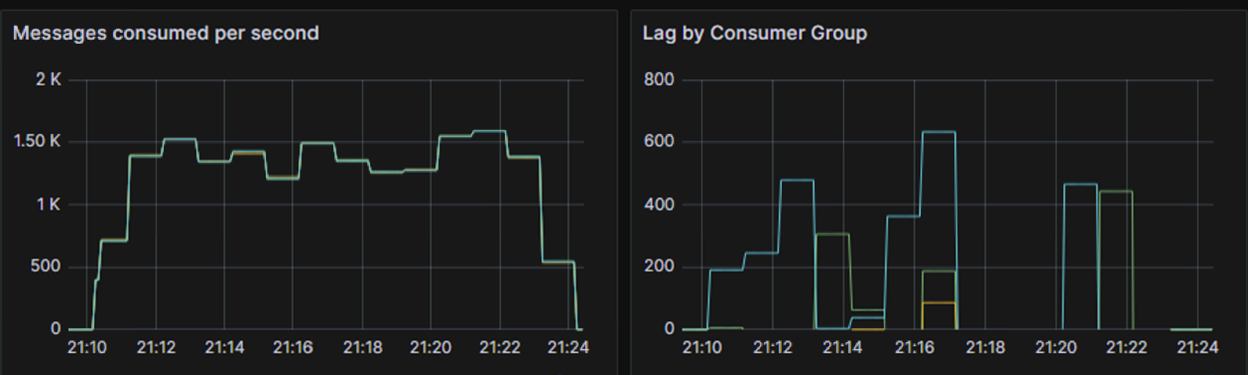
Na wykresie prezentującym liczbę wiadomości konsumowanych na sekundę (po lewej stronie), wykresy wszystkich aplikacji nachodzą na siebie co oznacza że aplikacje te osiągają niemal identyczne wartości procesowanych wiadomości na sekundę. Na wykresie prezentującym lag poszczególnych konsumentów (prawa strona) widać że żaden z nich nie rośnie, utrzymują się na niskim poziomie co jest pożądanym zachowaniem. Wynik jest o tyle niesamowity, że między pierwszym a drugim przebiegiem żadne inne parametry nie zostały zmienione, nie wprowadzono żadnych zmian w aplikacji a test wykonywano na tych samych serwerach. Wpływ tylko tych trzech parametrów na przepustowość jest ogromny.
Zaprezentowane wyżej wartości parametrów nie stanowią żadnej referencji albo jedynego słusznego rozwiązania. W każdym przypadku wartości tych parametrów mogą być inne i należy je dobrać z ‘głową’ na bazie testów wydajnościowych i specyfiki danego rozwiązania. Dodatkowo przed ‘kręceniem’ tymi parametrami powinniśmy zadbać, w pierwszej kolejności, o wydajność naszych aplikacji – w kontekście Kafki aplikacje te, zwłaszcza streamowe, powinny procesować wiadomości bardzo szybko tzn. na poziomie milisekund lub kilkunastu milisekund. Dłuższe czasy procesowania mogą spowodować, że nawet strojenie wskazanych wyżej parametrów nic nie zmieni.
Podsumowanie
Apache Kafka jest rozwiązaniem, które z powodzeniem może być używane w celu zapewnienia wydajnej i bezpiecznej komunikacji opartej o zdarzenia. W artykule starłem się zaadresować różne obszary funkcjonalne, która są podstawą dla działania takich systemów i muszą być uwzględnione w momencie ich wdrażania. Mam nadzieję że zebrane tu informacje pozwolą Wam w sposób efektywny używać Kafki. Celem artykułu było podzielenie się rzeczywistymi doświadczeniami projektowymi, a fakt że Kafka w wielu aspektach wypada świetnie to wyłącznie zasługa Kafki i nie jest to żadna forma lokowania produktu 😊


